EMPO Fully Unsupervised LLM Reasoning Incentivization
Recently, we explored a Fully Unsupervised LLM Reasoning Incentivization method and found it demonstrates surprisingly effective performance. Below, we provide a concise overview and analysis of the key insights from our research.
Paper: Right Question is Already Half the Answer: Fully Unsupervised LLM Reasoning Incentivization
Arxiv:https://arxiv.org/pdf/2504.05812 (First released on April 8, 2025)
GitHub:https://github.com/QingyangZhang/EMPO
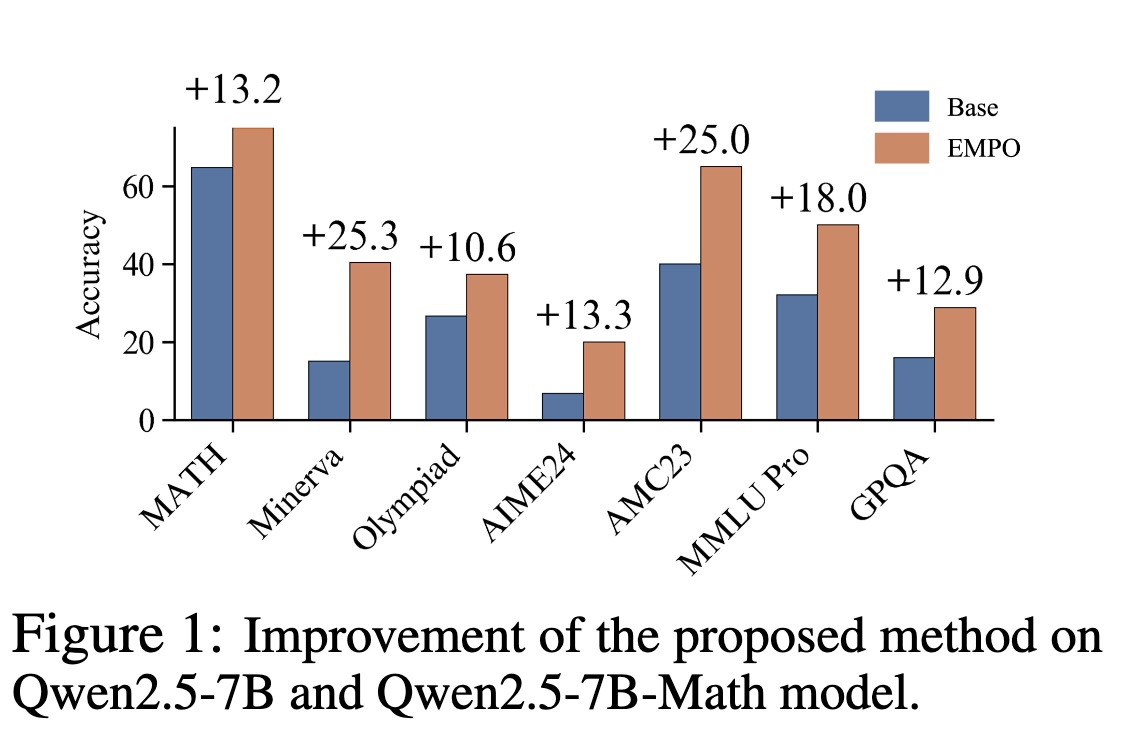
Motivation
Existing methods to enhance the reasoning capability of large language models predominantly rely on supervised fine-tuning (SFT) followed by reinforcement learning (RL) on reasoning-specific data. These approaches critically depend on external supervisions–such as labeled reasoning traces, verified golden answers, or pre-trained reward models. In this work, we propose Entropy Minimized Policy Optimization, which makes an early attempt at fully unsupervised LLM reasoning incentivization. By continuously minimizing the predictive entropy of LLMs on unlabeled questions in a latent semantic space, EMPO achieves competitive performance compared to supervised counterparts on both mathematical and free-form natural reasoning tasks. The key features of EMPO are:
-
Fully Unsupervised: EMPO directly trains the base model using reinforcement learning, skipping SFT or instruction tuning and dodging any need for human-annotated answers.
-
Task Generality: In each iteration, it samples multiple responses from the model, groups them into clusters based on semantic similarity, and the probability of these semantic clusters is used as a reward signal to drive learning. This makes EMPO applicable to general reasoning tasks beyond mathematics. By continuously minimizing the uncertainty (entropy) of responses at the semantic level, it overcomes limitations imposed by fixed answer formats.
Core Idea
We propose to leverage semantic entropy as an unsupervised optimization objective for incentivizing the reasoning capability of LLM. Semantic entropy is a natural and principled extension of classic Shannon entropy for LLMs. Semantic entropy has a strong negative relationship with model accuracy and thus can be used as a proxy minimizing objective. Given an input question, we first samples a group of output from the current model and then merges them into a set of meaning clusters Once built such a meaning set, \ours approximately minimizes the semantic entropy by rewarding the outputs contain high-likelihood meanings.
Performance
Without any supervised signals, EMPO boosts the accuracy of Qwen2.5-Math-7B Base from 30.7% to 48.1% on mathematical benchmarks and improves the accuracy of Qwen2.5-7B Base from 32.1% to 50.1% on MMLU-Pro.
Insights: The Role of Unsupervised Learning in Eliciting Pre-Trained Reasoning Capabilities
To dissect the nature of the improvements conferred by reinforcement learning (RL) post-training, we investigated its influence on pass@k accuracy. This metric is crucial as recent studies suggest that RL may not fundamentally expand the inherent reasoning capacities of LLMs beyond those already embedded in their pre-trained base. As depicted in the following Figure, our findings align with this perspective. Both GRPO and EMPO significantly enhance pass@k scores for small to moderate values of k (e.g., k=16 or 32) compared to the base model. This demonstrates an improved efficiency in surfacing correct reasoning paths with fewer attempts. However, as k becomes substantially large, the performance of these RL-trained models tends to converge with, and is sometimes surpassed by, that of the base model.

This convergence at high k values, coupled with our qualitative observations that the base models themselves already exhibit sophisticated reasoning behaviors such as pausing, self-correction, and backtracking (see Appendix for examples), strongly indicates that the foundational reasoning pathways are largely pre-existing. Consequently, RL post-training, whether supervised or unsupervised like EMPO, appears to primarily refine the model’s ability to efficiently access, prioritize, and consistently select these latent reasoning patterns, rather than instilling fundamentally novel ones. The observed improvements in pass@1 (accuracy) are thus likely a consequence of this enhanced sampling efficiency.
These empirical insights from the pass@k analysis lend considerable support to the emerging consensus that pre-training shoulders the primary burden of endowing LLMs with their core abilities. We align our interpretation with prior insights from previous work: `` Pretraining does all the hard work. One big bet is that the pretraining phase grants all the abilities to the base LM, and finetuning is simply like a style transfer which positions the model to the right output space.’’ Under this conjecture (or more precisely, an emerging, but not yet unanimously accepted consensus), we attribute the efficacy of our method to the robust pretraining process of the Qwen2.5 Base model: If a base model possesses strong inherent reasoning capabilities, the subsequent challenge is not necessarily to teach it new reasoning skills from scratch, but rather to effectively elicit and guide these existing skills.
EMPO’s success highlights that intrinsic reward signals, derived purely from the model’s objective to minimize semantic entropy and thus achieve greater consistency in its outputs, can be surprisingly potent for this elicitation process. In a well-pre-trained model, outputs that are semantically consistent are more likely to align with correct and coherent reasoning. EMPO leverages this by incentivizing the model to favor such consistent outputs, effectively guiding it to refine its selection from its collection of existing reasoning strategies without requiring external validation of correctness.
In conclusion, while RL techniques, including EMPO, may not be forging entirely new fundamental reasoning capabilities beyond what pre-training provides, their role in significantly enhancing the sampling efficiency and reliability of accessing these pre-trained abilities is of paramount practical importance. Optimizing models for such efficiency is crucial for real-world applications. Our EMPO, by achieving this through a fully unsupervised framework, offers a particularly scalable, cost-effective, and practical approach to unlocking and refining the vast reasoning potential embedded within pre-trained LLMs, especially in domains where curated supervisory data is scarce or prohibitively expensive to obtain.
Cite
@article{zhang2025right,
title = {Right question is already half the answer: Fully unsupervised llm reasoning incentivization},
author = {Zhang, Qingyang and Wu, Haitao and Zhang, Changqing and Zhao, Peilin and Bian, Yatao},
journal = {arXiv preprint arXiv:2504.05812},
year = {2025}
}
Enjoy Reading This Article?
Here are some more articles you might like to read next: